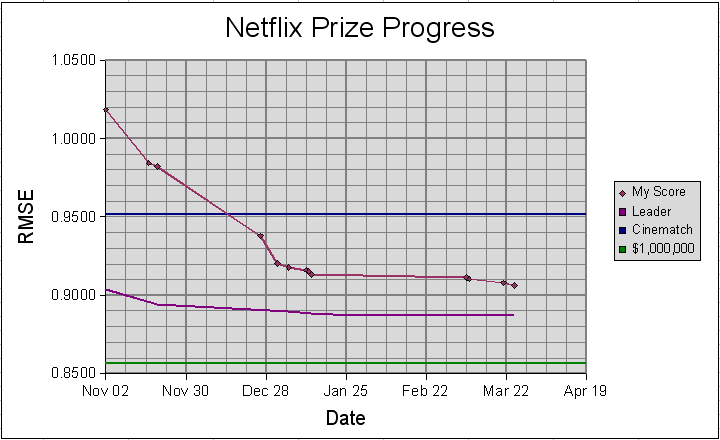
Between October, 2006 and March 2007 much of my free time was spent pursuing the Netflix Prize. Netflix was offering $1 million to anyone who could take the dataset they provided (containing 100 million ratings from 500 thousand customers covering 20 thousand movies) and make predictions for 2 million unknown ratings (from those same customers and movies) that were 10% better than Netflix's own predictions as measured by the root mean squared error (RMSE). The prize was eventually won.
Working on this challenge was fun and frustrating and a great learning experience. I worked on my early ideas in LISP before switching to C++ due to my inability to optimize LISP for performance. I exchanged the pain of slow execution for the pain of slow development and having to compile and reload all of the data into memory for each new test. I may eventually research LISP optimization (maybe using type declarations for all variables?) and write a language performance comparison page. I bet that would be a hit on Programming.Reddit.
If you came here hoping to read about my ideas or techniques I'm afraid my best scores come from using the ideas already discussed by others. I don't want you to go away empty handed so I compiled a list below of the web pages that helped me get my score.
- Simon Funk: Try This at Home
- Timely Development: Netflix Prize Results and Source Code
- Billy McCafferty: Using the Pearson Correlation Coefficient
- David Vogel / Ognian Asparouhov: Netflix Solution (link is no longer valid)
- Anil Thomas: Netflix Contest
-
Current Best Score
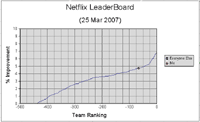
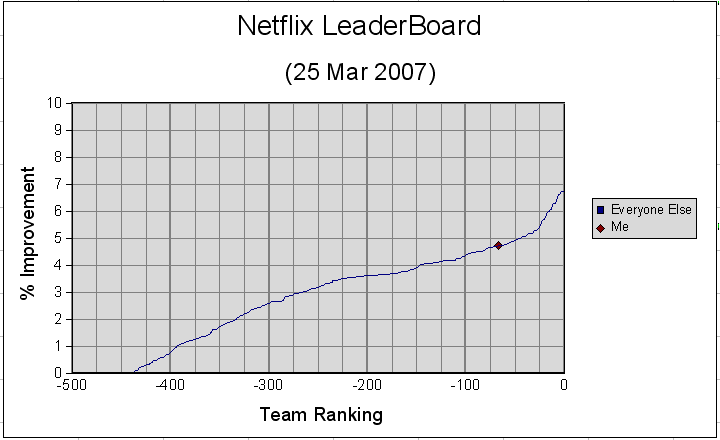
As of March 25th, 2007 my best score was 0.9064, a 4.73% improvement over Netflix and good enough for 67th place on the leaderboard. At the time there were 17,151 teams (1,702 had made a valid submission and 438 had beaten the netflix score of 0.9514).